
Database Sharding
Splitting Your Data Without Splitting Your Sanity

Introduction
Imagine you run a library. At first, one building holds all the books, and a single catalogue helps visitors find what they need. But the library grows. The shelves overflow, the aisles are packed, and the catalogue desk has a line out the door. You have two choices: build a bigger building (vertical scaling) or open multiple branches across the city and distribute the collection (horizontal scaling).
Database sharding is the second option. It’s the practice of splitting your data across multiple database instances, called shards, so that no single server has to bear the entire load. In this post, we’ll explore how sharding works, the strategies you can use, how to pick the right shard key, and the real-world pain of cross-shard queries. By the end, you’ll have a solid understanding of when sharding makes sense and how companies like Instagram, Discord, and Slack have implemented it at scale.
Let’s get started!
What Is Database Sharding?
Sharding is a form of horizontal partitioning where rows of a database table are distributed across multiple independent database instances. Each shard holds a subset of the data, and together they represent the complete dataset.
Unlike read replicas (which duplicate the entire dataset for read scaling), sharding splits the data itself. This means both reads 𝘢𝘯𝘥 writes scale horizontally, something replicas alone cannot achieve.
Going back to our library analogy: read replicas are like printing extra copies of the catalogue so more people can look things up at the same time. Sharding is like distributing the actual books across multiple branches, so no single building runs out of shelf space.
Sharding Strategies
There are three primary strategies for deciding which shard holds which data. Each comes with trade-offs.
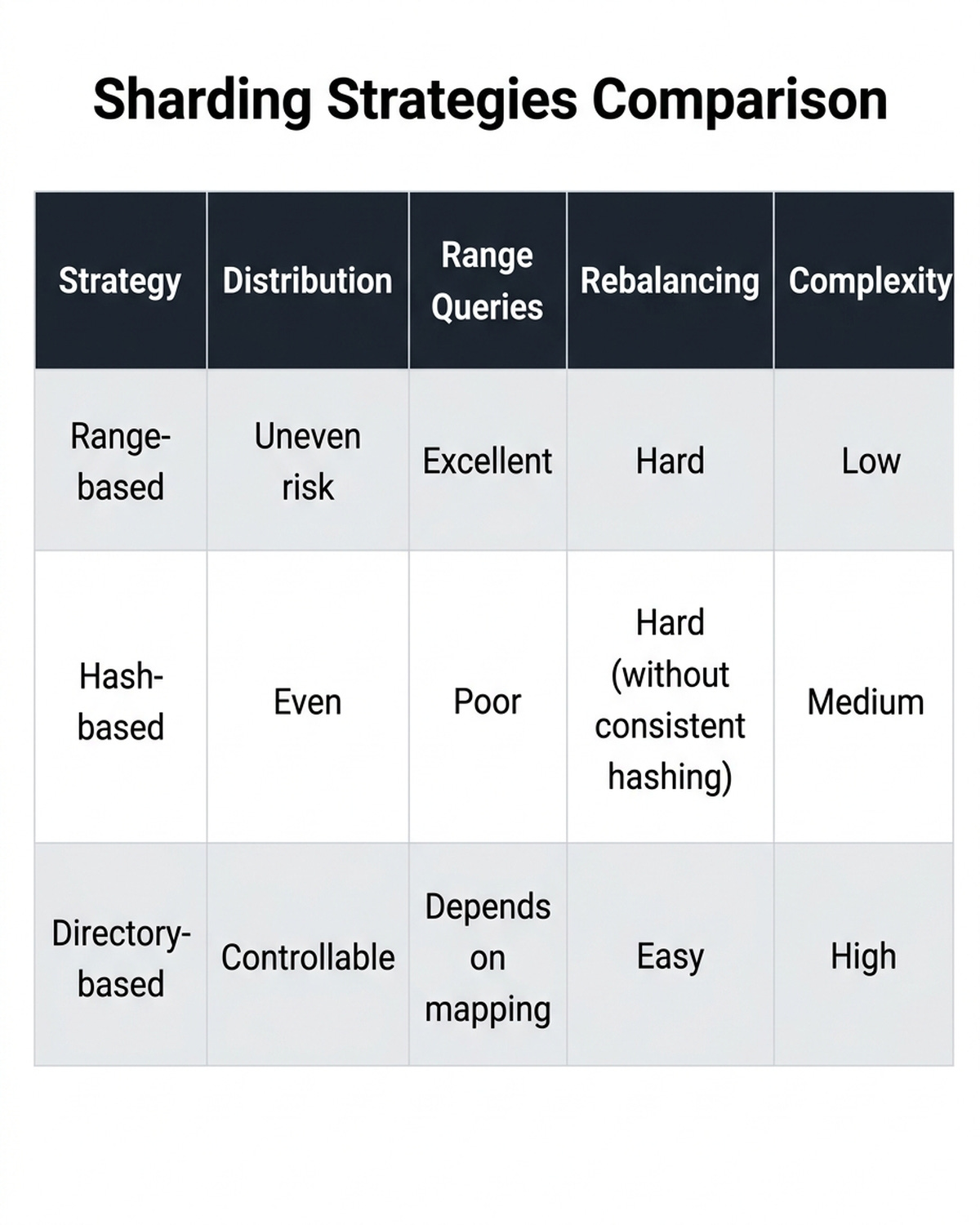
Range-Based Sharding
Data is partitioned based on continuous ranges of the shard key. For example, user IDs 1 to 1,000,000 go to Shard A, 1,000,001 to 2,000,000 go to Shard B, and so on.
Advantages:
Keeps adjacent data together, making range scans efficient
Simple to implement and easy to reason about
Disadvantages:
Creates hotspots when new data clusters at one end of the range (the shard holding the newest data gets hammered with writes)
Leads to unbalanced shards over time
Best for: Time-series data where range queries are the dominant access pattern.
Hash-Based Sharding
A hash function is applied to the shard key, and the result determines which shard stores the record:
shard_number = hash(user_id) % number_of_shardsAdvantages:
Distributes data and traffic most evenly across shards
Dramatically reduces hotspot risk
Disadvantages:
Range queries become expensive; fetching user IDs 2M to 3M may scatter across hundreds of shards, forcing scatter-gather operations
Adding or removing shards changes the modulo value, meaning most keys need rehashing
This is the most common general-purpose strategy. To mitigate the rehashing problem, many systems use consistent hashing, where data and servers are placed on a virtual ring. Adding a node only requires redistributing roughly 1/N of the data, rather than rehashing everything.
Best for: High-write workloads with primarily point lookups (get by ID).
Directory-Based (Lookup) Sharding
A centralised lookup table maps shard keys to specific shards. Every query first consults this directory to find the target shard.
Advantages:
Maximum flexibility: move users between shards without changing application logic
Isolate high-traffic tenants onto dedicated shards
Disadvantages:
The directory itself can become a bottleneck or a single point of failure
Cache misses on the directory introduce extra network hops
Best for: Multi-tenant systems where tenants vary wildly in size.
Here’s a quick comparison:
Choosing the Right Shard Key
If sharding is the commitment, the shard key is the marriage vow. Get it wrong, and you’ll feel the pain for years. Here’s what makes a good shard key:
High cardinality: The key must have many unique values. A user_id with millions of values is far better than a continent with only 7. Low cardinality literally caps how many effective shards you can have.
Even distribution: The ideal key distributes data roughly equally across all shards.
Alignment with query patterns: Choose a key that appears in your most common WHERE clauses. If most queries filter by customer_id, that should be your shard key. When queries lack a shard key, they become scatter-gather queries that are broadcast to every shard.
Immutability: The shard key should rarely (or never) change. Updating it means physically moving a row between shards.
Common Mistakes
1. Monotonically increasing keys (timestamps, auto-increment IDs) with range-based sharding: all new inserts hit the last shard forever, creating a permanent write hotspot.
2. Low-cardinality fields like status or country: you can never have more effective shards than you have distinct values.
3. Misalignment with queries: Sharding by region when queries primarily filter by customer_id forces every customer query to scan all shards.
The Cross-Shard Query Problem
This is where the real pain lives. Sharding breaks the relational model. If a user’s account lives on Shard 1 and their transaction record lives on Shard 2, you can’t use a single database transaction or a simple JOIN.
Think of it like our library branches: if a researcher needs books from three different branches, they can’t just walk to one shelf. They need to visit (or call) each branch, collect the results, and piece together what they need.
Solutions
1. Data Colocation (Prevention is Better Than Cure)
Design your schema so related data lands on the same shard. For example, if you shard by user_id, make sure a user’s orders, preferences, and activity logs all use user_id as the shard key. This is the most important technique. Avoid cross-shard queries by design.
Pinterest does exactly this: when inserting a Pin, they prefer to place it on the same shard as its parent board.
2. Reference Tables (Broadcast Tables)
Replicate small, slowly-changing tables (countries, categories, config) across all shards. Joins against reference data become local operations.
3. Eventual Consistency / CQRS
Accept that some queries will be eventually consistent. Materialise cross-shard views asynchronously, separating read models from write models.
4. Modified Two-Phase Commit
Dropbox’s Edgestore uses a modified 2PC with an external durable transaction record for cross-shard transactions. The leader writes a durable transaction record before the cross-shard operation, and concurrent requests only need to check this record to determine the transaction state. This approach handles 10 million requests per second across thousands of MySQL nodes, with only 5-10% of transactions being cross-shard.
Real-World Examples
Instagram: Embedded Shard IDs
Instagram chose sharded PostgreSQL over NoSQL solutions. Their 64-bit ID scheme encodes the shard directly into the primary key:
| 41 bits: timestamp | 13 bits: shard ID | 10 bits: sequence |By reading the ID, the application knows exactly which shard to query. No lookup table needed. This supports 8,192 logical shards and 1,024 IDs per millisecond per shard.
Discord: From Cassandra to ScyllaDB
Discord stored trillions of messages across 177 Cassandra nodes, but hot partitions and JVM garbage collector pauses caused latency spikes. They migrated to ScyllaDB (a Cassandra-compatible database written in C++), reducing their cluster to 72 nodes while dropping p99 read latency from 40-125ms to just 15ms.
Slack: Vitess Migration
Slack spent three years migrating 99% of their MySQL traffic to Vitess, an open-source sharding middleware. At peak, they handle 2.3 million queries per second (2M reads, 300K writes). The migration eliminated database hotspots and enabled new features like Slack Connect and international data residency.
When Should You Actually Shard?
Sharding should be a last resort. Before you commit, exhaust these options first:
1. Vertical scaling (more RAM, faster CPU, SSD)
2. Read replicas for read-heavy workloads
3. Query optimisation and better indexing
4. Caching layers (Redis, Memcached)
5. Connection pooling
6. Table partitioning (single-node)
Shard when:
Your data physically doesn’t fit on one machine
Write throughput exceeds what one server can handle
You need geographic data residency for compliance (GDPR)
You’ve tried everything above, and it’s still not enough
Conclusion
Database sharding is a powerful scaling tool, but it’s not free. It introduces operational complexity: schema changes must be coordinated across all shards, backups become more involved, monitoring must cover every shard, and failure modes multiply.
The companies that do it well, Instagram, Discord, Slack, Pinterest, all share a common trait: they designed their shard key and data model 𝘣𝘦𝘧𝘰𝘳𝘦 sharding, not after. They colocated related data, planned for resharding from day one, and built routing layers to keep application code clean.
If you’re considering sharding, start with the shard key. Get that right, and most of the other problems become manageable. Get it wrong, and you’ll have a distributed system that’s slower and harder to operate than the single database you started with.
That’s it for this post. If you want to explore further, I recommend reading Instagram’s engineering blog on their ID generation scheme and Slack’s write-up on their Vitess migration. Both are excellent examples of sharding done well.